百度文心一言怎么样?文心一言评测介绍
作者:小Q 人气: 39文心一言昨天正式发布了,而邀请通道也正式放开了,不少企业也在第一时间申请了内测,而最新的测评消息也已经出来了哟,那么百度文心一言怎么样?下面小编就给大家分享下最新的信息,让你及时的了解具体的测评结果。

文心一言评测介绍:
初体验带来的惊喜
在获得体验资格后,很多读者期待我们用这些问题来测试文心一言。
下图中为 GPT-4 为文心一言设计的测试题,从文学、翻译、创作、逻辑推理等多个角度测试,在网上也广为流传。

那么结果如何?我们挑选了几个有代表性的回答来看。
首先是翻译问题,要求翻译成「优美」的中文诗句。效果确实很赞。

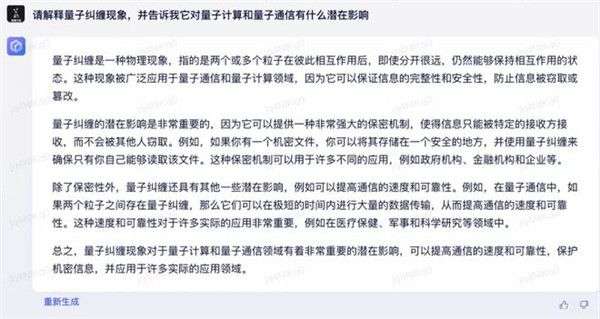
然后是量子纠缠的科学问题,从结果来看知识性的回答效果不错。
最后的逻辑推理问题:回答有缺陷。但从结果中我们明显可以看出文心一言是的确进行分析了,有思维链,但是结果不对。

然后,我们也测试了一个在 ChatGPT 上经常玩的梗,文心一言也能拿捏。

另外,文心一言也具备多模态生成能力,包括生成图片、生成语音(包括方言)以及生成视频的能力。
以生成图片为例,我们让文心一言生成了一张湖心亭看雪的水墨画,生成速度、效果都挺令人满意的。

现场李彦宏 Demo 的生成视频的能力给观众留下深刻印象。但目前还未开放,期待后续的更新。
一番体验下来, 文心一言真的超乎了我们的预期。目前来看,脑暴的题目答的很好;翻译和文生图的效果真的很赞;写代码能力还有很大的提升空间。虽然有的问题也会和 ChatGPT 一样「胡说八道」,但毕竟崭新出炉,相信后续迭代会有提升。
专注中文理解与生成
揭秘文心一言背后的关键技术
体验完文心一言,我们来了解下其背后的技术。在昨天的发布会上,百度 CTO 王海峰总结介绍了文心一言背后的关键技术。
从整体来看,百度文心一言基于知识增强千亿大模型 ERNIE,同时借鉴了文心对话大模型 PLATO,二者的技术都在文心一言身上得到了延伸,在训练过程中不断改进。
具体来讲,文心一言包含了六个核心技术模块,分别是有监督精调、人类反馈的强化学习、提示以及知识增强、检索增强和对话增强。其中前三类技术是对话大模型都会用到的,后三类技术为百度已有技术优势的再创新,它们共同构筑了文心一言的技术根基,并在对话效果上得到充分释放和呈现。

持续优化对话大模型通用技术
针对有监督精调,除了标准的有监督精调技术,百度也做了针对性的优化。首先文心一言做了更多中文标注数据,基于对中国语言文化和中文应用场景的理解来选择数据,因而在中文任务上更好用。其次服务应用,百度在为其个人用户和企业客户服务中积累了大量对应用需求的理解,在精调数据时发挥了作用。最后富含知识,除了将知识图谱应用在知识增强过程中,还基于知识图谱产生了很多事实证明有效的数据来用于数据精调。

我们知道,OpenAI 在调优 ChatGPT 时使用了监督学习和强化学习的组合,其中强化学习组件用到了人类反馈的强化学习(RLHF)训练机制,使得模型在训练中使用人类反馈以最小化无益、失真或偏见的输出。
百度也非常看重 RLHF 机制在训练中的重要性,提出了一套完整的技术,也被证明非常有效。首先接收人类反馈,然后使用反馈数据来训练奖励模型,最后再做强化学习的策略优化。但应看到,由于文心一言刚刚上线,用户需求和反馈数据尚不充分,因而后续一定会基于更多真实反馈获得进化。

提示(prompt)已经成为与大模型尤其是对话大模型互动最自然直观的方式。千亿以上参数的大模型往往蕴含了极其丰富的数据和知识,如何快速准确找到并应用这些数据和知识变得至关重要。这时提示构建得好不好将直接影响语言模型表现出的能力,因此文心一言在这方面下了大功夫。
当用户输入提示时可以基于很多自动构建的方法来提升效果,比如补充实例(解题时给出示例)、创作时给出提纲、规范等。此外大语言模型也会出现错误,这时加入已知的准确知识点也能提升回答准确性。最后在构建提示时加入思维链也会使答案更合理,逻辑更清晰。

独特优势构成文心一言强大根基
除了继续强化打磨大语言模型的通用技术,百度还针对知识增强、检索增强和对话增强三个已有优势进行再创新。
知识增强是文心大模型的核心特色之一,通过从海量的知识和数据中融合学习,模型能够实现更高的效率、更好的效果、更强的可解释性。做到这些需要两方面的技术 —— 知识内化和知识外用。知识内化是从大规模知识和无标注数据中,基于语义单元学习,利用知识构造训练数据,将知识学习到模型参数中;知识外用是指知识在模型参数中未内化进去,但在推理过程中引入外部多源异构知识,做知识推理、提示构建等。
此外通过知识图谱来构建训练数据,达到知识内化的效果。百度拥有世界上最大的多源异构知识图谱,包含了 50 亿实体和 5500 亿事实,并在不断演进和更新。除了基于知识图谱进行知识推理,还可以基于知识来构建提示。

百度在搜索领域拥有很多领先技术,每天响应几十亿次真实的用户使用需求。发展到了今天,百度新一代搜索架构已经发展到了基于语义理解和匹配,其中文心大模型分别理解用户输入和文档,形成双塔模型,然后基于理解进行匹配。
这套搜索架构与包括文心一言在内的文心大模型有着天然不可分的关联,在做生成模型时可以进行联合优化,将检索中一些有价值的结果(如精准的信息)带入生成过程。通过引入搜索结果,为大模型提供时效性强、准确率高的参考信息,更好地满足用户需求。

百度在对话领域同样拥有很多对话技术和应用积累。我们知道,对话很多时候不是一个问题和一个答案,有上下文的多轮对话才是常态,因此记忆机制和上下文理解都很重要。同时长对话还要考虑对话规划,这些结合起来才能实现更好的对话连贯性、合理性和逻辑性。

可以看到,打造出一个出色的大模型哪有那么容易,在技术上需要持续创新。AI 研发就像烧一壶开水,比 100℃更难的是从 0℃到 99℃。王海峰表示,文心一言是百度多年技术积累和产业实践的水到渠成。
这一切可以追溯到 2010 年,彼时深度学习尚未大火,百度即开始全面布局人工智能,是全球为数不多、进行全栈布局的人工智能公司。从底层芯片到框架、模型和应用,百度都拥有领先的自研技术和产品,通过层与层之间的相互反馈、端到端优化提升效率,贯通整个 AI 全产业链。
尤其飞桨深度学习平台和文心大模型的联合优化为文心一言提供了坚实的技术支撑。飞桨支撑了文心一言从开发训练到推理部署的整个流程,在开发训练层面,飞桨动静统一的开发范式和自适应分布式架构,实现大模型的灵活开发和高效训练;在推理部署层面,飞桨支持大模型高效推理,提供服务化部署能力,包括计算融合、软硬协同的稀疏量化、模型压缩等。

同时,文心大模型自 2019 年发布 ERNIE 1.0 以来,已经全面涵盖了 NLP、CV、跨模态、生物计算以及行业大模型,并基于大模型推出了 AI 作画产品文心一格和产业级搜索系统文心百中。
飞桨深度学习平台和文心大模型是支撑文心一言的底气。文心一言还延续了文心大模型知识增强的特色,通过理解和生成能力的集成获得极大助益。
作为国内搜索领域的头号玩家,在可预见的未来,百度或将凭借文心一言引领中文搜索市场的代际变革,为用户带来更便捷友好的搜索体验。此外以文心一言为契机的大语言模型和生成式 AI 也将助力金融、能源、媒体、政务等千行百业的智能化变革。
正如李彦宏在会上所说,「百度希望和大家一起,推动人工智能技术进步,让所有人都能使用最先进的生产力工具,让所有人都能从中受益。」
最后感慨一句,ChatGPT、GPT-4 的连番发布,让我们一直忧心中国 AI 技术能否跟上海外的步伐。昨天百度的新闻发布会,我们能看到有人调侃吐槽,但也看到更多人愿意抱着宽容的态度看待百度勇敢迈出的第一步。期待在百度的这一步之后,更多中国企业能够走的更远。
加载全部内容